SFT and Online RL for Visual Generation: How We Built CoSprite's Training Pipeline
How Cumulus built a production pipeline for consistent AI-generated game previews using best-of-N sampling, deterministic rendering, pairwise judging, supervised fine-tuning, and online reinforcement learning with GRPO.
We built a generation pipeline that took CoSprite's game preview system from 88% render success to 94%—and laid the groundwork for continuous improvement through online RL.
CoSprite came to us for GPU serving. We started deploying their models on our infrastructure, looked at their training workflow, and found bigger problems than inference speed.
Their system generates AI-powered game previews—static visual outputs rendered from code. Individual outputs could look great. Across thousands of prompts, quality fell apart. Blank canvases, broken layouts, partial renders. The model worked in demos. It didn't work in production.
Prompt engineering helped on specific inputs but didn't generalize. Rejection sampling improved things, but costs scaled linearly—more candidates, more GPU time, more judging calls to Gemini 3 Pro. Diminishing returns set in fast.
The constraints were strict: canvas & JS only (no CSS cheating), specific aspect ratios, static previews (not playable games), and no labeled data to train against. Manual annotation wasn't feasible.
We needed two things: a pipeline that could reliably surface good outputs from a noisy generator, and a training loop that could make the generator less noisy over time.
Why Single-Shot Scoring Doesn't Work
The obvious approach—generate one candidate per prompt, assign an absolute visual score, threshold it—breaks down for constrained visual tasks.
The core issue is that visual correctness in this domain is largely binary. A canvas is either blank or it isn't. A layout is either clipped or it isn't. Absolute scoring maps poorly onto these failure modes—a small but critical defect like text running off the edge might only drop the score by a point, but it renders the output unusable.
This creates an unstable tradeoff. Tighten the acceptance threshold and rejection rates spike, making the system impractical across diverse prompts. Loosen it and broken outputs slip through. In practice, single-shot generation with absolute scoring optimizes for average quality when what production requires is consistent correctness—a fundamentally different objective.
The Pipeline
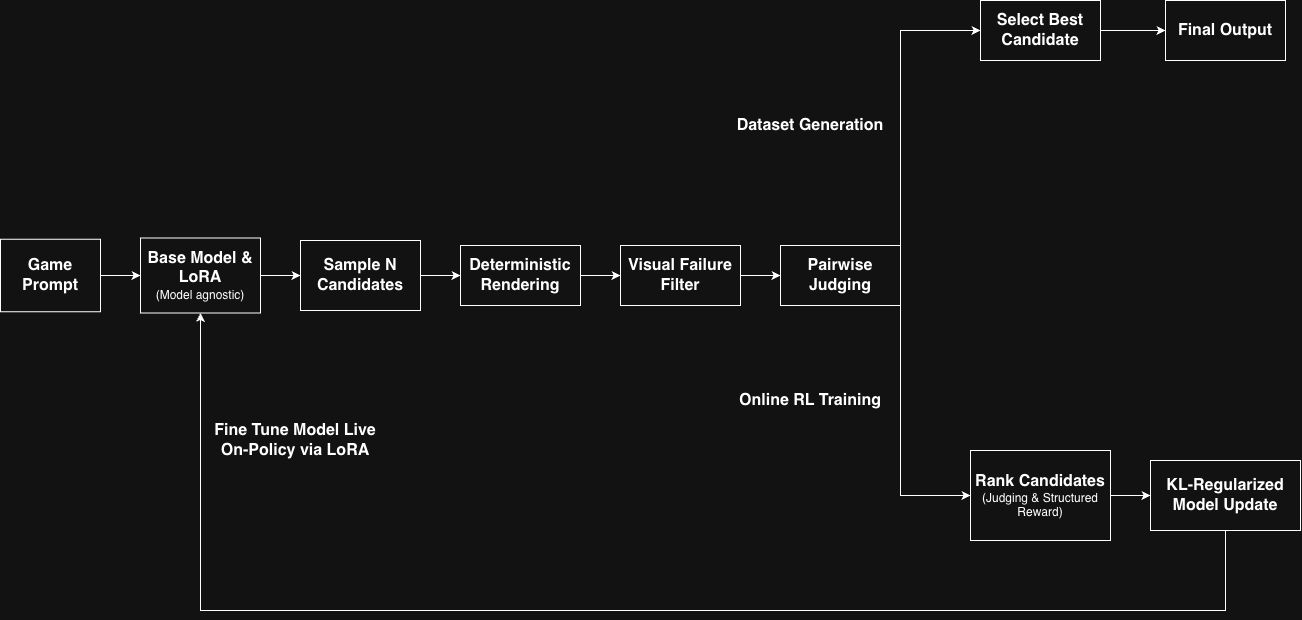
Rather than trying to make the model perfect in one shot, we built a system that generates multiple candidates and reliably picks the best one.
Best-of-N sampling. For each prompt, generate multiple candidates. Let the model explore freely at generation time. Enforce correctness downstream.
Deterministic rendering. Extract the JavaScript from each candidate, wrap it in a fixed HTML template (portrait or landscape), render it in Playwright with a locked viewport. Anything that fails to execute or produces malformed output gets cut immediately.
Visual failure filtering. Before invoking expensive judges, filter out blank screens, broken layouts, cut-off elements, and text overlap. Fail fast on the obvious stuff.
Pairwise judging. This was the key design decision. Absolute scores were unreliable for subtle layout differences—a 17/25 and an 18/25 might look identical, or one might be clearly better. Pairwise comparisons reduce the problem to a simpler question: which of these two better satisfies the constraints? We structured this as a tournament-style selection process, keeping comparisons localized within each prompt to avoid cross-prompt score contamination.
The pipeline ran local inference on Cumulus infrastructure and treated all models uniformly. This model-agnostic design meant improvements to the underlying model or architecture required no changes to the evaluation logic.
The full system, including the optional online RL training loop:
Training: SFT First, Then RL
With the pipeline generating labeled data at scale, we explored two complementary training strategies—supervised fine-tuning to establish structural reliability, followed by reinforcement learning to optimize for visual quality through preference signals.
Supervised Fine-Tuning
We curated a dataset of high-quality candidates from the pipeline's rejection sampling and automated filtering stages. These served as training data for an SFT stage that taught the model the correct output structure—renderable JavaScript, proper formatting, the visual patterns that survive deterministic rendering.
SFT proved effective at improving structural reliability. Fewer blank canvases, fewer broken layouts, more outputs that actually render. However, supervised fine-tuning does not explicitly optimize for relative quality between multiple valid candidates. The model learns to imitate good examples, but doesn't learn to rank subtle visual differences—layout composition, element spacing, visual balance—between outputs that all technically render.
We treated SFT as stage one: establish a strong baseline that reliably produces renderable outputs. Then optimize for quality.
GRPO: Online Reinforcement Learning
Stage two used Group Relative Policy Optimization (GRPO)—a true on-policy training loop, distinct from the static rejection sampling used earlier.
At each training step, the current policy samples multiple completions per prompt. An external judge ranks the candidates. Rankings are converted into structured rewards: higher-ranked outputs receive positive values, broken outputs receive penalties, and rewards are mean-centered within each group to compute advantages. The policy then updates via a KL-regularized policy gradient objective applied to LoRA parameters, ensuring the model doesn't drift too far from the reference distribution while still learning from preference differences.
The loop repeats with fresh data generated from the updated policy at each step. This is the critical distinction from rejection sampling—instead of filtering a static dataset, the judge's signal feeds directly into gradient updates. Pairwise judging transforms from a selection mechanism into an optimization signal. The model explores, the judge evaluates, and the policy shifts.
To maintain training stability, we enforced deterministic judge prompts, strict output parsing with retry logic for transient failures, and KL regularization against the reference model. These safeguards ensured reward signals remained consistent across training steps.
Reward Design
The reward signal was designed to reflect both output quality and deployment efficiency:
- Higher-ranked candidates received larger positive rewards
- Lower-ranked candidates received smaller or negative rewards
- Explicit penalties for blank outputs, rendering failures, or structurally broken responses
- A token-efficiency penalty discouraged verbose generations, creating pressure toward structured, efficient code rather than sprawling output
This meant the model was optimizing under a joint objective: produce outputs that rank higher visually and cost less to serve. The efficiency penalty is particularly important for production—shorter, well-structured generations reduce both inference latency and GPU cost.
Results
To validate the pipeline, we compared training strategies on a held-out set of 50 prompts using identical generation settings. Gemini scoring used a 5-dimensional scale, each category weighing 5 points (max 25). Candidates from all trained models and the baseline were evaluated using pairwise A/B comparisons with randomized ordering.
| Model | Render Success | Mean Gemini Score |
|---|---|---|
| Baseline (MiniMax-M2.5) | 88% | 19.27 |
| SFT | 94% | 20.85 |
| GRPO | 92% | 19.59 |
Supervised fine-tuning produced the strongest results. Render success increased from 88% to 94%, and Gemini-judged visual quality improved by +2.64 points on average. A paired comparison across prompts showed the SFT model improved results on 64% of prompts, with statistically significant gains.
GRPO validated that the preference-optimization pipeline could train stably end-to-end. The model maintained strong render rates and demonstrated that on-policy learning from pairwise judging rewards functioned as intended. With additional training iterations and expanded evaluation signals, this loop is positioned for continued improvement.
For production systems, improvements of this magnitude are significant. Each percentage point of render reliability translates directly to fewer retries, lower latency, and reduced GPU waste downstream.
The production system currently deploys the SFT model. The reinforcement learning pipeline remains integrated into the system and can be activated for continued optimization as additional training data becomes available.
The Broader Point
The interesting thing about this project isn't any one technique. It's that model quality alone wasn't enough.
CoSprite's base model could produce great outputs. The problem was that it couldn't do it reliably, across thousands of prompts, under real constraints. Fixing that required building a system around the model—generation, rendering, filtering, judging, training—where quality emerges from the interaction between components, not from the model alone.
That's the pattern we keep seeing. The model is one piece. The infrastructure that makes it work in production is the rest.
If you're building generative AI systems that need to work reliably at scale, come talk to us.