5 VLMs, 1 GPU: Beating Together AI on Price and Throughput
Cheap GPU inference for AI models: we ran 5 VLMs on one GPU and matched Together AI's throughput at a fraction of the cost. Serverless GPU vs dedicated GPU economics.
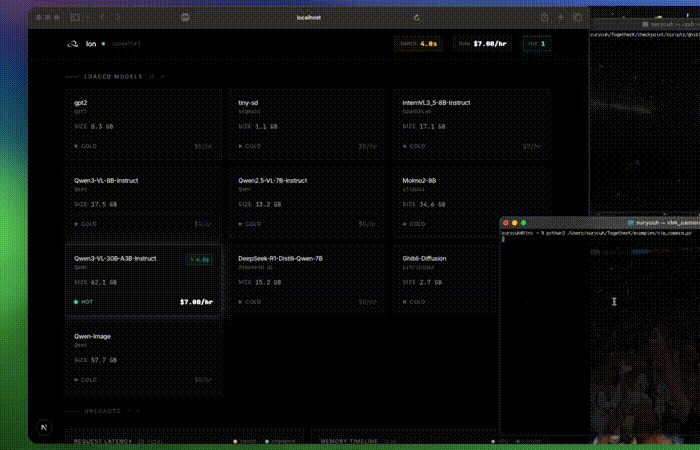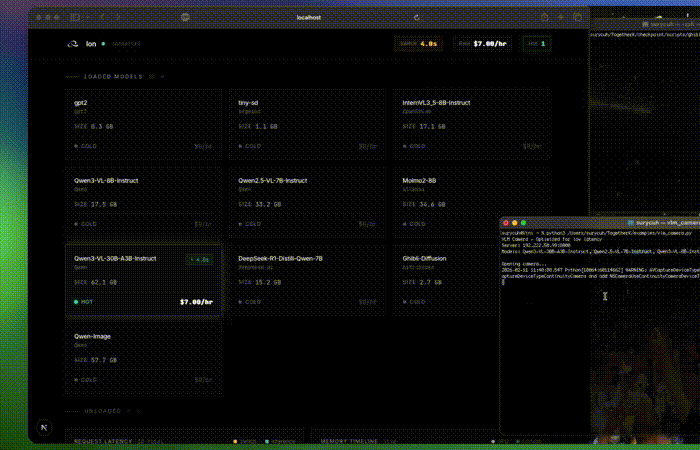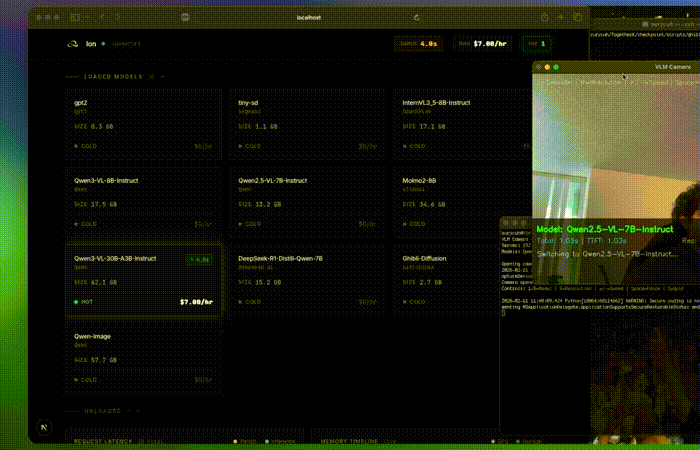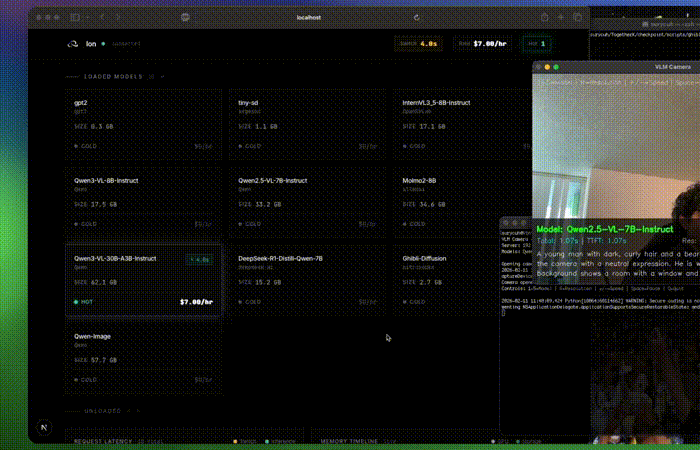
We ran 5 vision models on one GPU and matched Together AI's throughput.
Together AI charges $0.50 per million input tokens and $1.50 per million output tokens for Qwen3-VL-32B. That adds up fast when you're processing video — vision tokens are expensive, and video workloads produce a lot of them.
We run on GH200s instead of H100s. Same or better throughput. Lower cost basis. And we match their per-token pricing.
But Together only supports a handful of models. What about your finetuned Qwen? Your custom LoRA? The new VLM that shipped on HuggingFace last Tuesday?
For those, your only option today is renting a dedicated GPU at $3-7/hour. Running 24/7. Mostly idle.
That's the problem we built Cumulus Labs to solve.
One GPU. Five Models. The Full Picture.
We benchmarked five vision-language models against Together AI using real video workloads under concurrent load.
All five ran on a single GPU.
| Model | Cumulus (GH200) | Together | Cumulus Latency P50 / P95 |
|---|---|---|---|
| Qwen3-VL-8B | 588 tok/s | 298 tok/s (+97%) | 3.2s / 5.1s |
| Qwen3-VL-30B-A3B | 478 tok/s | 435 tok/s (+10%) | 4.1s / 6.2s |
| Qwen3-VL-32B | 241 tok/s | 222 tok/s (+8%) | 3.6s / 6.0s |
| Molmo2-8B | 1,293 tok/s | 1,277 tok/s (+1%) | 2.4s / 4.0s |
| MiniCPM-V-4.5 | 982 tok/s | 1,064 tok/s (92%) | 2.6s / 4.6s |
We're showing latency because we think honest benchmarks matter more than cherry-picked wins. At high concurrency, we're 1-2 seconds slower on first-token response than a dedicated H100. For batch video processing and async pipelines, that's irrelevant. For interactive chat where every millisecond counts, it matters.
These aren't synthetic benchmarks. Every number comes from real video inference — 2,700 clips at varying lengths, frame rates, and resolutions, sent through the standard OpenAI-compatible API with dozens of concurrent users.
The Problem: Models They Don't Support
Together AI hosts popular base models. That works for a lot of people. But production AI doesn't live on base models alone.
You finetune Qwen3-VL on your proprietary data. You train a custom LoRA for your document format. You need MiniCPM-V-4.5 for one pipeline and a specialized diffusion model for another. Maybe you're running an open-source model that shipped last week and no provider has added it yet.
For any of these, your options today are:
- Rent a dedicated GPU — $2.99-6.98/hr for an H100, running 24/7 regardless of traffic. A single model costs $2,150-5,000+/month, mostly idle.
- Serverless GPU providers — Modal, Baseten, RunPod — charge per second, which helps. But cold starts hit 30-60+ seconds for a 32B model. So you keep instances warm, and you're back to paying for idle.
Three custom models on dedicated GPUs? $6,000-15,000/month. If each is only active 30% of the time, you're burning 70% of that.
How We Price It
Popular models we support: Per-token pricing, matching Together AI's rates. Same price, same or better throughput.
Everything else — finetuned models, custom LoRAs, unsupported models: Per-GPU-second pricing. Bring any model. You pay for the seconds of GPU time you actually use. Not hours. Not 24/7. Seconds.
| Scenario | Together AI | Cumulus Labs |
|---|---|---|
| Qwen3-VL-32B (base) | $0.50 / $1.50 per 1M tokens | $0.50 / $1.50 per 1M tokens |
| Molmo2-8B (base) | $0.20 / $0.20 per 1M tokens | $0.20 / $0.20 per 1M tokens |
| Your finetuned Qwen3-VL-32B | Dedicated H100 — $2,419/mo | Per GPU-second |
| Custom LoRA variant | Dedicated H100 — $2,419/mo | Per GPU-second |
| Brand new open-source VLM | Not yet listed | Per GPU-second |
The base model comparison is simple: same price, same or better speed.
The custom model comparison is where it changes. Instead of $2,419/month for a dedicated H100 running 24/7, you pay for the seconds your model is actually doing work. A finetuned 32B VLM handling 1,000 video requests per day might use 2-3 hours of actual GPU time — a fraction of the always-on cost.
Why This Works: Fast Model Switching
We can offer per-GPU-second pricing without cold start penalties because we don't cold start.
ionattention, our inference engine, keeps 50+ models ready to serve on a single chip. When a request comes in, your model is already loaded. When traffic drops, the GPU is instantly available for other workloads.
| Dedicated GPU | Serverless (Modal, etc.) | Cumulus Labs | |
|---|---|---|---|
| Cold start | None (always on) | 30-60+ seconds | Seconds |
| Idle cost | Full GPU cost 24/7 | Warm instances or cold starts | None |
| Multiple models | 1 GPU per model | 1 instance per model | 50+ models, 1 GPU |
| Pricing | $/hour | $/second | $/token or $/GPU-second |
What We Learned About VLMs in Production
Token compression is everything. MiniCPM-V-4.5 and Qwen2.5-VL-7B are both ~8B parameter models. MiniCPM hit 982 tok/s at 36 concurrent streams. Qwen2.5-VL maxed out at 43 tok/s with 5 streams. The difference is how they tokenize video — MiniCPM compresses aggressively (~64 tokens per 6 frames), Qwen2.5-VL produces 17,000+ for the same content. If you're choosing a VLM for video, benchmark tokens-per-frame first.
MoE and dense models saturate differently. Qwen3-VL-30B-A3B (30B total, 3B active) peaks at 12 concurrent streams. MiniCPM-V-4.5 (8B dense) needs 36. Don't plan capacity the same way for both.
Peak throughput is a vanity metric. The recommended operating point was 15-25% below peak for every model — the point where throughput is high and new users aren't stuck waiting.
What We're Building
Cumulus Labs is inference as a service — for any model, priced so you never pay for idle.
Popular models? Per-token pricing, matching the market. Your custom models? Per-GPU-second, billed only when inference is running. All of it on hardware that matches or beats the fastest providers.
If you're running finetuned or open source models of any kind, come talk to us. We'll meet your needs for cheaper.